Data Model
Reservoir uses Neo4j as its graph database to store conversations and their relationships. This section provides a detailed overview of the data model, including nodes, relationships, and how they work together to enable intelligent conversation management.
Overview
The data model is designed around the concept of messages as nodes in a graph, with relationships that capture both the conversational flow and semantic similarities. This approach enables powerful querying capabilities for context enrichment and conversation analysis.
Nodes
MessageNode
Represents a single message in a conversation, whether from a user or an LLM assistant.
| Property | Type | Description |
|---|---|---|
trace_id | String | Unique identifier per request/response pair |
partition | String | Logical namespace from URL, typically the system username ($USER) |
instance | String | Specific context within partition, typically the application name |
role | String | Role of the message (user or assistant) |
content | String | The text content of the message |
timestamp | DateTime | When the message was created (ISO 8601 format) |
embedding | Vector | Vector representation of the message for similarity search |
url | String | Optional URL associated with the message |
Example MessageNode
CREATE (m:MessageNode {
trace_id: "abc123-def456-ghi789",
partition: "alice",
instance: "code-assistant",
role: "user",
content: "How do I implement a binary search tree?",
timestamp: "2024-01-15T10:30:00Z",
embedding: [0.1, -0.2, 0.3, ...],
url: null
})
Relationships
The data model uses two types of relationships to capture different aspects of conversation structure:
RESPONDED_WITH
Links a user message to its corresponding assistant response, preserving the original conversation flow.
Properties:
- Direction:
(User Message)-[:RESPONDED_WITH]->(Assistant Message) - Cardinality: One-to-one (each user message has exactly one assistant response)
- Mutability: Immutable once created
Purpose:
- Maintains conversation integrity
- Enables reconstruction of original conversation threads
- Provides audit trail for request/response pairs
SYNAPSE
Links semantically similar messages based on vector similarity, enabling cross-conversation context discovery.
Properties:
- Direction: Bidirectional (similarity is symmetric)
- Score: Float value representing similarity strength (0.0 to 1.0)
- Threshold: Minimum score of 0.85 required for synapse creation
- Mutability: Dynamic (can be created, updated, or removed)
Creation Rules:
- Sequential Synapses: Initially created between consecutive messages in a conversation
- Similarity Synapses: Created between messages with high semantic similarity (≥ 0.85)
- Cross-Conversation: Can link messages from different conversations within the same partition/instance
- Pruning: Synapses with scores below threshold are automatically removed
Example Synapse
(m1:MessageNode)-[:SYNAPSE {score: 0.92}]-(m2:MessageNode)
Graph Structure Example
┌─────────────────┐ RESPONDED_WITH ┌─────────────────┐
│ User Message │────────────────────→│Assistant Message│
│ "Explain BST" │ │ "A binary..." │
└─────────────────┘ └─────────────────┘
│ │
│ SYNAPSE │ SYNAPSE
│ {score: 0.91} │ {score: 0.87}
▼ ▼
┌─────────────────┐ RESPONDED_WITH ┌─────────────────┐
│ User Message │────────────────────→│Assistant Message│
│ "How to code │ │ "Here's how..." │
│ tree search?" │ │ │
└─────────────────┘ └─────────────────┘
Real Conversation Graph Visualization
Here's an example of how conversations and their threads appear in practice, showing the synapse relationships that connect semantically related messages across different conversation flows:
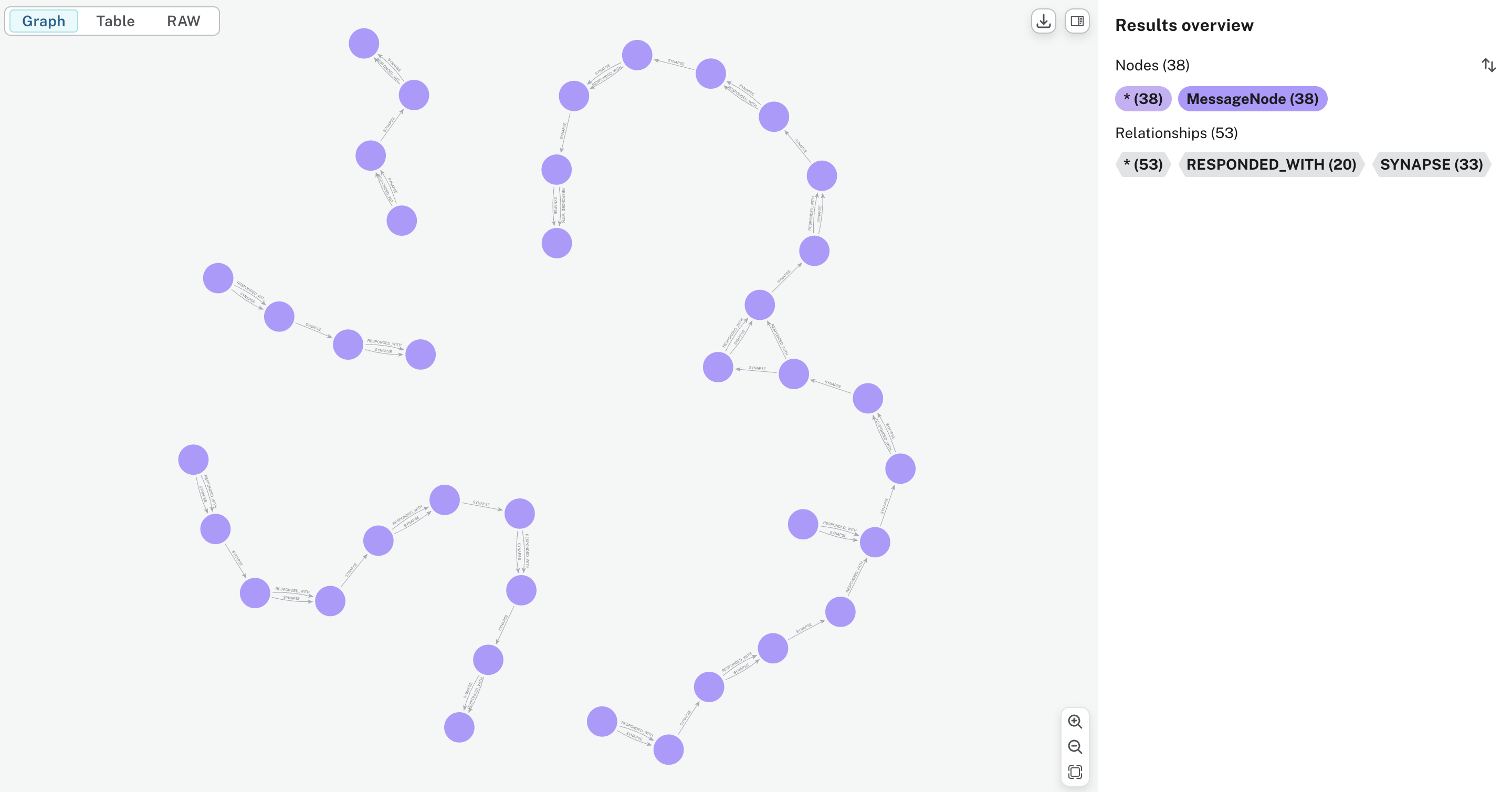
This visualization shows:
- Message nodes representing individual user and assistant messages
- RESPONDED_WITH relationships (direct conversation flow)
- SYNAPSE relationships connecting semantically similar messages
- Conversation threads formed by chains of related messages
- Cross-conversation connections where topics are discussed in multiple conversations
The graph structure enables Reservoir to find relevant context from past conversations when enriching new requests, creating a rich conversational memory that spans multiple sessions and topics.
Vector Index
Reservoir maintains a vector index called messageEmbeddings in Neo4j for efficient similarity searches.
Index Configuration
CREATE VECTOR INDEX messageEmbeddings
FOR (m:MessageNode) ON (m.embedding)
OPTIONS {indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}}
Similarity Search
The vector index enables fast cosine similarity searches:
CALL db.index.vector.queryNodes('messageEmbeddings', 10, $queryEmbedding)
YIELD node, score
WHERE node.partition = $partition AND node.instance = $instance
RETURN node, score
ORDER BY score DESC
Partitioning Strategy
Partition
- Purpose: Top-level organization boundary
- Typical Value: System username (
$USER) - Scope: All messages for a specific user
- Isolation: Messages from different partitions never interact
Instance
- Purpose: Application-specific context within a partition
- Typical Value: Application name (e.g., "code-assistant", "chat-app")
- Scope: Specific use case or application context
- Organization: Multiple instances can exist within a partition
Example Organization
Partition: "alice"
├── Instance: "code-assistant"
│ ├── Programming questions
│ └── Code review discussions
├── Instance: "research-helper"
│ ├── Literature reviews
│ └── Data analysis questions
└── Instance: "personal-chat"
├── General conversations
└── Daily planning
Relationship Types: Fixed vs. Dynamic
Fixed Relationships
Characteristics:
- Immutable once created
- Preserve data integrity
- Represent factual conversation structure
Examples:
MessageNodeproperties (once created, content doesn't change)RESPONDED_WITHrelationships (permanent conversation pairs)
Dynamic Relationships
Characteristics:
- Mutable and adaptive
- Support learning and optimization
- Reflect current understanding of semantic relationships
Examples:
SYNAPSErelationships (can be created, updated, or removed)- Similarity scores (can be recalculated as algorithms improve)
Query Patterns
Context Enrichment Query
// Find recent and similar messages for context
MATCH (m:MessageNode)
WHERE m.partition = $partition
AND m.instance = $instance
AND m.timestamp > $recentThreshold
WITH m
ORDER BY m.timestamp DESC
LIMIT 10
UNION
CALL db.index.vector.queryNodes('messageEmbeddings', 5, $queryEmbedding)
YIELD node, score
WHERE node.partition = $partition
AND node.instance = $instance
AND score > 0.85
RETURN node, score
ORDER BY score DESC
Conversation Thread Reconstruction
// Reconstruct a conversation thread
MATCH (user:MessageNode {role: 'user'})-[:RESPONDED_WITH]->(assistant:MessageNode)
WHERE user.trace_id = $traceId
RETURN user, assistant
ORDER BY user.timestamp
Synapse Network Analysis
// Find highly connected messages (conversation hubs)
MATCH (m:MessageNode)-[s:SYNAPSE]-(related:MessageNode)
WHERE m.partition = $partition AND m.instance = $instance
WITH m, count(s) as connectionCount, avg(s.score) as avgScore
WHERE connectionCount > 3
RETURN m, connectionCount, avgScore
ORDER BY connectionCount DESC, avgScore DESC
Data Lifecycle
Message Storage
- Ingestion: New messages are stored with embeddings
- Indexing: Vector embeddings are indexed for similarity search
- Relationship Creation:
RESPONDED_WITHlinks are established - Synapse Building: Similar messages are connected via
SYNAPSErelationships
Synapse Evolution
- Initial Creation: Sequential synapses between consecutive messages
- Similarity Detection: Cross-conversation synapses based on semantic similarity
- Threshold Enforcement: Weak synapses (score < 0.85) are removed
- Continuous Optimization: Relationships are updated as new messages arrive
Cleanup and Maintenance
- Orphaned Relationships: Periodic cleanup of broken relationships
- Index Optimization: Regular vector index maintenance
- Storage Optimization: Archival of old messages based on retention policies
Performance Considerations
Indexing Strategy
- Vector Index: Primary index for similarity searches
- Partition/Instance Index: Composite index for scoped queries
- Timestamp Index: Range queries for recent messages
- Role Index: Fast filtering by message role
Query Optimization
- Parameterized Queries: Use query parameters to enable plan caching
- Result Limiting: Always limit result sets for performance
- Selective Filtering: Apply partition/instance filters early
- Vector Search Tuning: Optimize similarity thresholds and result counts
Scaling Considerations
- Horizontal Partitioning: Distribute data across multiple Neo4j instances
- Read Replicas: Use read replicas for query-heavy workloads
- Connection Pooling: Efficient database connection management
- Batch Operations: Use batch writes for bulk data operations
This data model provides a robust foundation for conversation storage and retrieval while maintaining flexibility for future enhancements and optimizations.